CLUSTERING IN R

Description of Clustering
It is basically a type of unsupervised learning method . An unsupervised learning method is a method in which we draw references from datasets consisting of input data without labeled responses. Generally, it is used as a process to find meaningful structure, explanatory underlying processes, generative features, and groupings inherent in a set of examples.
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups. It is basically a collection of objects on the basis of similarity and dissimilarity between them.
Role / Importance
The application of cluster analysis in data mining has two main aspects: first, clustering analysis can be used as a pre-processing step for the other algorithms such as features and classification algorithm, and also can be used for further correlation analysis. Second, it can be used as a stand-alone tool in order to get the data distribution, to observe each cluster features, then focus on a specific cluster for some further analysis. Cluster analysis can be available in market segmentation, target customer orientation, performance assessment, biological species etc.
PROBLEM - Bird Data Set
Source Code
bird <- read.csv('C:/sk/bird.csv')
names(bird)
bird.new<- bird[,c(2,3,4,5,6,7,8,9,10,11)]
bird.class<- bird[,"type"]
bird.new
normalize <- function(x){
return ((x-min(x))/(max(x)-min(x)))
}
bird.new$huml<- normalize(bird.new$huml)
bird.new$humw<- normalize(bird.new$humw)
bird.new$ulnal<- normalize(bird.new$ulnal)
bird.new$ulnaw<- normalize(bird.new$ulnaw)
bird.new$feml<- normalize(bird.new$feml)
bird.new$femw<- normalize(bird.new$femw)
bird.new$tibl<- normalize(bird.new$tibl)
bird.new$tibw<- normalize(bird.new$tibw)
bird.new$tarl<- normalize(bird.new$tarl)
bird.new$tarw<- normalize(bird.new$tarw)
head(bird.new)
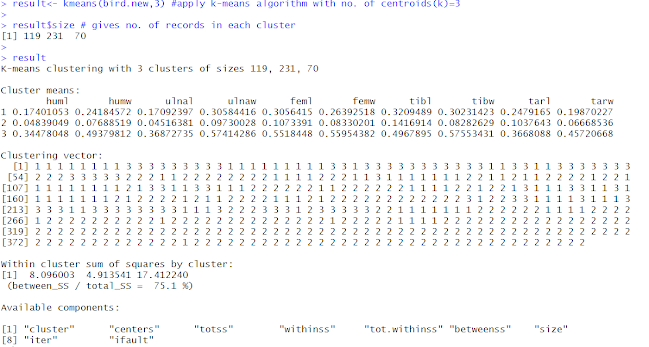
result<- kmeans(bird.new,3) #apply k-means algorithm with no. of centroids(k)=3
result$size # gives no. of records in each cluster
result
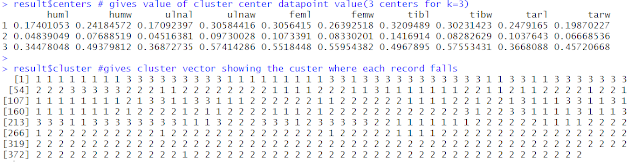
result$centers # gives value of cluster center datapoint value(3 centers for k=3)
result$cluster #gives cluster vector showing the custer where each record falls
clusplot(bird,result$cluster,color = TRUE,shade = TRUE,labels = 2,lines = 0)
clusters <- hclust(dist(bird[,2:3]))
plot(clusters)
clusters <- hclust(dist(bird[,2:3]),method = "average")
plot(clusters)
library(ggplot2)
result$cluster <- as.factor(result$cluster)
ggplot(bird, aes(huml, humw, color = bird.class)) + geom_point()
result$cluster <- as.factor(result$cluster)
ggplot(bird, aes(ulnal, ulnaw, color = bird.class)) + geom_point()
result$cluster <- as.factor(result$cluster)
ggplot(bird, aes(feml, femw, color = bird.class)) + geom_point()
result$cluster <- as.factor(result$cluster)
ggplot(bird, aes(tibl, tibw, color = bird.class)) + geom_point()
result$cluster <- as.factor(result$cluster)
ggplot(bird, aes(tarl, tarw, color = bird.class)) + geom_point()
table(result$cluster,bird.class)
OUTPUT
Preprocess the dataset
Since clustering is a type of Unsupervised Learning, we would not require Class Label(type) during execution of our algorithm. We will, therefore, remove Class Attribute “type” and store it in another variable.

Normalisation is used to eliminate redundant data and ensures that good quality clusters are generated which can improve the efficiency of clustering algorithms.

Apply k-means clustering algorithm
One measurement is Within Cluster Sum of Squares (WCSS), which measures the squared average distance of all the points within a cluster to the cluster centroid.
Another measurement is Between Clusters Sum of Squares (BCSS), which measures the squared average distance between all centroids. BCSS measures the variation between all clusters.
Using 3 groups (K = 3) we had 75.1% of well-grouped data.


Plot to see how huml and humw data points have been distributed in clusters as per bird types
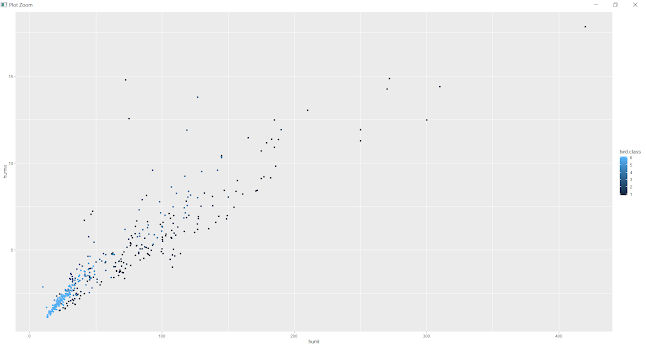
Most Swimming birds and wading birds have the longest humerus bone and other birds have short humerus bone
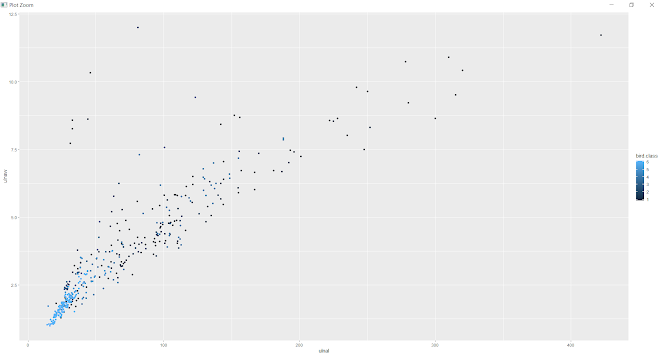
Most Swimming birds and wading birds have the longest ulna bone and other birds have short ulna bone
Most Swimming birds and wading birds have the longest femur bone and other birds have short femur bone
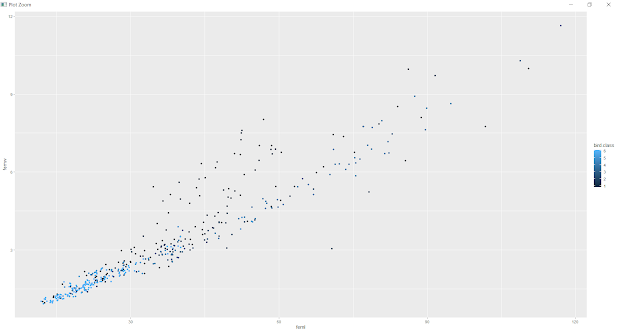

Most Swimming birds and wading birds have the longest Tibiotarsus bone and other birds have short Tibiotarsus bone
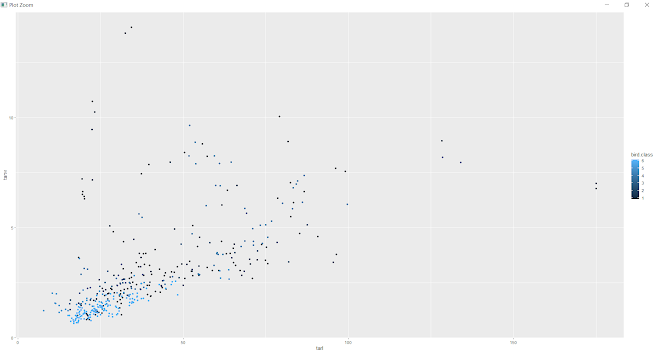
Most Swimming birds and wading birds have the medium sized Tarsometatarsus bone and other birds have short Tarsometatarsus bone

Comments
Post a Comment