CLUSTERING IN R

Description of Clustering
It is basically a type of unsupervised learning method . An unsupervised learning method is a method in which we draw references from datasets consisting of input data without labeled responses. Generally, it is used as a process to find meaningful structure, explanatory underlying processes, generative features, and groupings inherent in a set of examples.
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups. It is basically a collection of objects on the basis of similarity and dissimilarity between them.
Role / Importance
The application of cluster analysis in data mining has two main aspects: first, clustering analysis can be used as a pre-processing step for the other algorithms such as features and classification algorithm, and also can be used for further correlation analysis. Second, it can be used as a stand-alone tool in order to get the data distribution, to observe each cluster features, then focus on a specific cluster for some further analysis. Cluster analysis can be available in market segmentation, target customer orientation, performance assessment, biological species etc.
PROBLEM - Iris Data Set
Source Code
data("iris")
names(iris)
new_data<-subset(iris,select = c(-Species))
new_data
cl<-kmeans(new_data,3)
cl
data <- new_data
wss <- sapply(1:15,function(k){kmeans(data, k )$tot.withinss})
wss
plot(1:15, wss,
type="b", pch = 19, frame = FALSE,
xlab="Number of clusters K",
ylab="Total within-clusters sum of squares")
install.packages("cluster")
library(cluster)
clusplot(new_data, cl$cluster, color=TRUE, shade=TRUE,labels=2, lines=0)
cl$cluster
cl$centers
"agglomarative clustering "
clusters <- hclust(dist(iris[, 3:4]))
plot(clusters)
clusterCut <- cutree(clusters, 3)
table(clusterCut, iris$Species)
library(ggplot2)
ggplot(iris, aes(Petal.Length, Petal.Width, color = iris$Species)) +
geom_point(alpha = 0.4, size = 3.5) + geom_point(col = clusterCut) +
scale_color_manual(values = c('black', 'red', 'green'))
clusters <- hclust(dist(iris[, 3:4]), method = 'average')
clusterCut1 <- cutree(clusters, 3)
table(clusterCut1, iris$Species)
plot(clusters)
ggplot(iris, aes(Petal.Length, Petal.Width, color = iris$Species)) +
geom_point(alpha = 0.4, size = 3.5) + geom_point(col = clusterCut1) +
scale_color_manual(values = c('black', 'red', 'green'))
Output
names - to get or set the names of an object.


Perform k-means clustering on a data matrix with 3 clusters with mean 3 random mean value
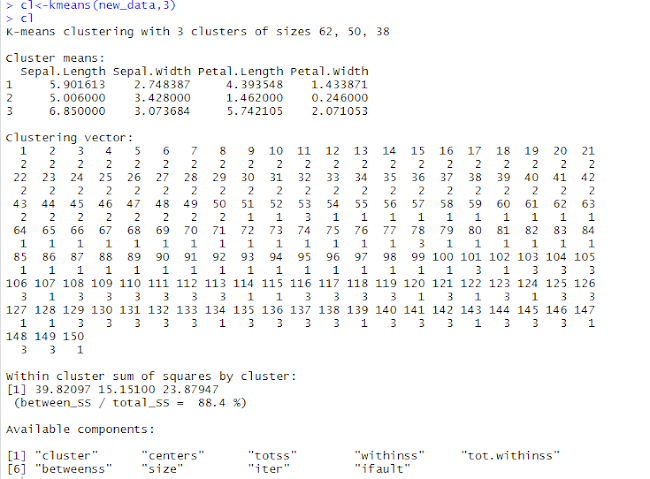
The sum of the squared deviations from each observation and the cluster centroid.
The within-cluster sum of squares is a measure of the variability of the observations within each cluster. In general, a cluster that has a small sum of squares is more compact than a cluster that has a large sum of squares. Clusters that have higher values exhibit greater variability of the observations within the cluster.

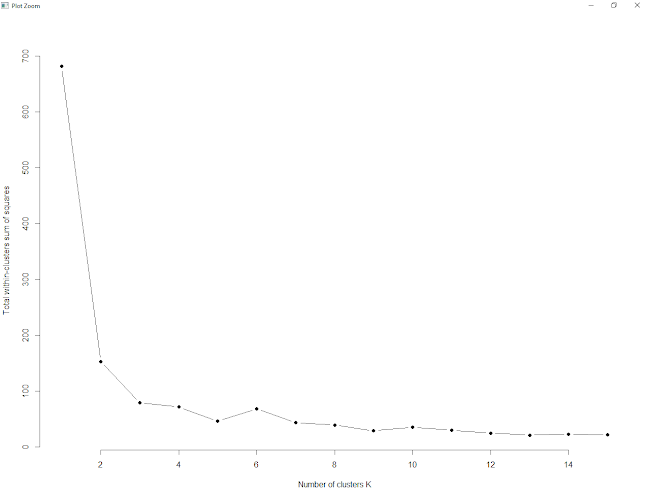
There are 3 clusters. 10 to 15 clustering is good.





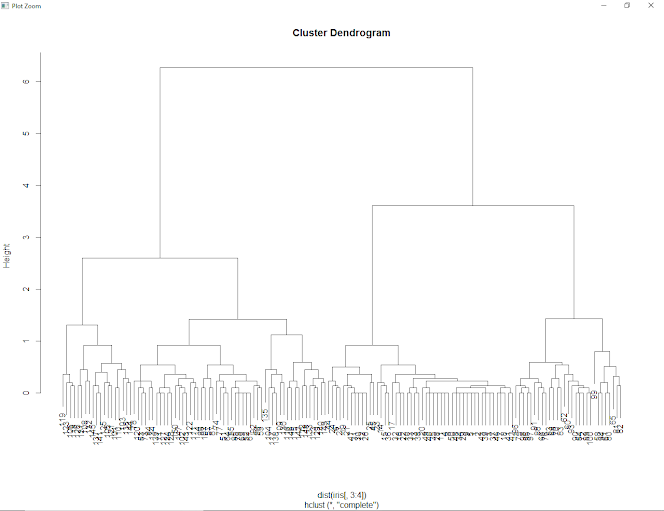


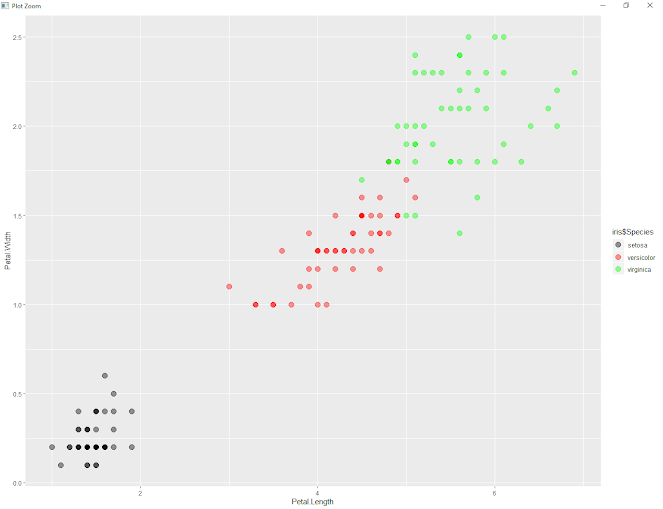
Virginica has maximum clustering.




Comments
Post a Comment