PREDICTION

Description of Logistic Regression
Logistic regression is a statistical analysis method used to predict a data value based on prior observations of a data set. Logistic regression has become an important tool in the discipline of machine learning. The approach allows an algorithm being used in a machine learning application to classify incoming data based on historical data. As more relevant data comes in, the algorithm should get better at predicting classifications within data sets. Logistic regression can also play a role in data preparation activities by allowing data sets to be put into specifically predefined buckets during the extract, transform, load (ETL) process in order to stage the information for analysis.
Role / Importance
Logistic Regression is a Machine Learning classification algorithm that is used to predict the probability of a categorical dependent variable. In logistic regression, the dependent variable is a binary variable that contains data coded as 1 (yes, success, etc.) or 0 (no, failure, etc.). In other words, the logistic regression model predicts P(Y=1) as a function of X.
PROBLEM : BANK LOAN
Source Code
#read data in R
cr<-read.csv(file.choose(),header = T,sep = ",")
View(cr)
#notice blanks were not changed to NA while reading.
#so change the above code using c(""," ")
cr<-read.csv(file.choose(),header = T,na.strings=c(""," ","NA"))
class(cr$DEFAULTER)
#convert categorical variable to factor
cr$DEFAULTER=as.factor(cr$DEFAULTER)
boxplot(cr)
#Splitting
set.seed(1234)
pd<-sample(2,nrow(cr),replace = TRUE, prob=c(0.8,0.2))#two samples with distribution 0.8 and 0.2
trainingset<-cr[pd==1,]#first partition
validationset<-cr[pd==2,]#second partition
#Model fitting
attach(trainingset)
model1 <- glm(DEFAULTER~.,family=binomial(link='logit'),data=trainingset)
summary(model1)
#assessing the predictive ability of the model: Validation
#read the test model
#validation of our model using validation set
pred <- predict(model1,newdata=validationset,type='response')
pred_status <- ifelse(pred >=0.75,1,0)
pred_status
#confusionmatrix
cf1<-table(pred_status,validationset$DEFAULTER)
cf1
library(ROCR)
p=prediction(pred_status,validationset$DEFAULTER)
roc=performance(p,'tpr','fpr')
plot(roc)
auc=performance(p,'auc')
Output
Selecting file and reading data

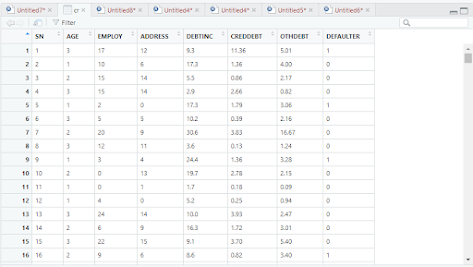
notice blanks were not changed to NA while reading.
so change the above code using c(""," ")
The na.strings argument is for substitution within the body of the file, that is, matching strings that should be replaced with NA.

convert categorical variable to factor
As far as categorical variables are concerned, using the read.table() or read.csv() by default will encode the categorical variables as factors. A factor is how R deals categorical variables.

Total 700 data variables are present in the data. All the data in each column is lying between 0 to 100. There are outliers present in employ, address, debtinc, creddebt, othdebt.
set.seed() in R is a pseudo-random number generator. It runs a function based on some inputs to produce what looks like random numbers. The first input in this randomization function is called the ‘seed’. For each ‘seed’ (n), R will return the same random values. This is highly valuable when you need your “random” results to be reproducible.

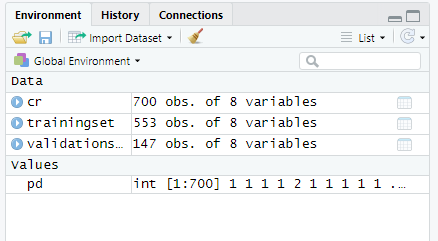
We split the data into two chunks: training and validation set. The training set will be used to fit our model which we will be testing over the validation set.


By using function summary() we obtain the results of our model

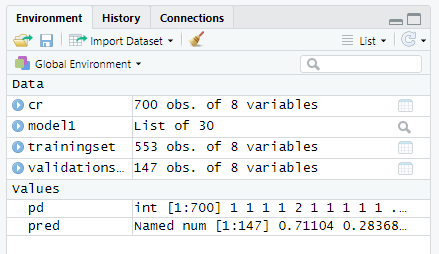

Assessing the predictive ability of the model




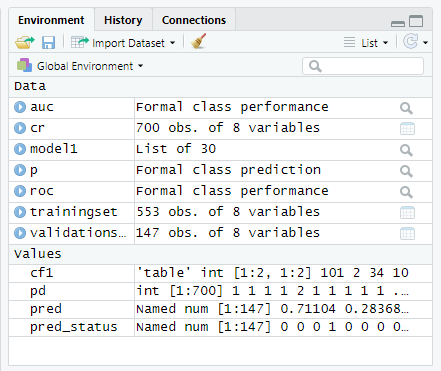

Conclusion
we plot the ROC curve and calculate the AUC (area under the curve) which are typical performance measurements for a binary classifier.
The ROC is a curve generated by plotting the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings while the AUC is the area under the ROC curve. As a rule of thumb, a model with good predictive ability should have an AUC closer to 1 (1 is ideal) than to 0.5.
Comments
Post a Comment