PRINCIPLE COMPONENT ANALYSIS

Description of principal component analysis
Principal-component analysis proposed by Hotelling (1933) is one of the most familiar methods of multivariate analysis which uses the spectral decomposition of a correlation coefficient or covariance matrix.
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components.
Role / Importance
The main idea of principal component analysis (PCA) is to reduce the dimensionality of a data set consisting of many variables correlated with each other, either heavily or lightly, while retaining the variation present in the dataset, up to the maximum extent. The same is done by transforming the variables to a new set of variables, which are known as the principal components (or simply, the PCs) and are orthogonal, ordered such that the retention of variation present in the original variables decreases as we move down in the order. So, in this way, the 1st principal component retains maximum variation that was present in the original components. The principal components are the eigenvectors of a covariance matrix, and hence they are orthogonal.
PROBLEM - Iris Data
Source Code
install.packages("pls")
diabet<-read.csv('C:/diabetes.csv')
head(diabet)
summary(diabet)
library()
"to find principal component"
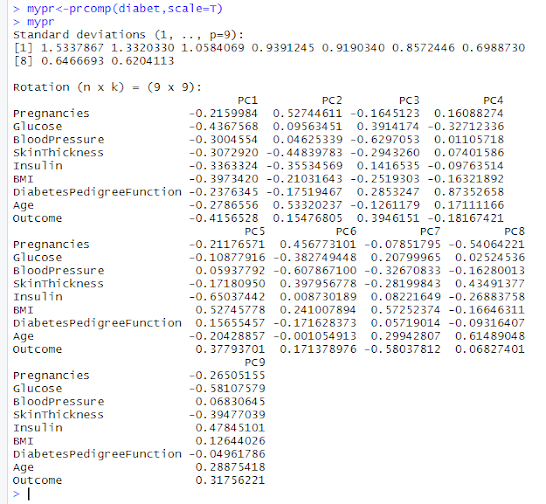
mypr<-prcomp(diabet,scale=T)
"to understand use of scale"
plot(diabet$Pregnancies,diabet$BMI)
plot(scale(diabet$Pregnancies),scale(diabet$BMI))
mypr
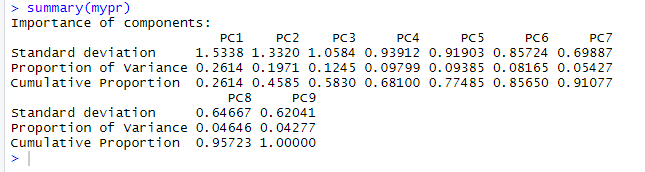
summary(mypr)
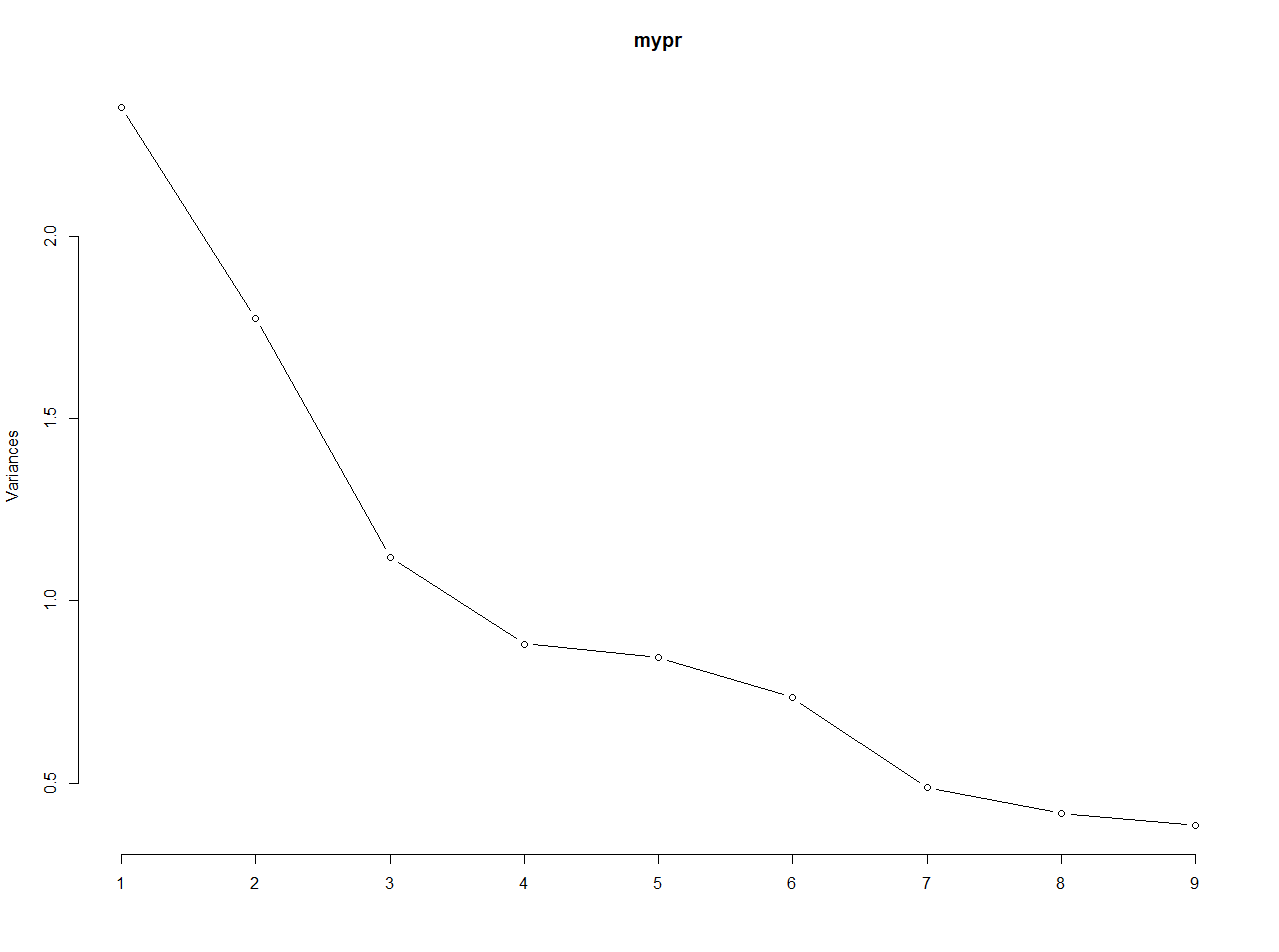
plot(mypr,type="l")
biplot(mypr,scale=0)
"extract pc scores"
str(mypr)
mypr$x
diabetes<-cbind(diabet,mypr$x[,1:2])
head(diabetes)
cor(diabet,diabetes)
library(pls)
pcmodel<-pcr(diabet$Outcome~diabet$Pregnancies+diabet$BMI+diabet$BloodPressure+diabet$SkinThickness,ncomp=3,data=diabet)
diabet$pred<-predict(pcmodel,diabet,ncomp = 2)
head(diabet)
Output

Find the principal component
Scale=TRUE means we are scaling the data before PCA.

No correlation
Summarizing the PCA objects
Plot the variance explained by principal components
plot the biplot showing first two PC’s and the original feature vectors in this 2D space i.e original feature vectors as linear combination of first two PC’s



Taking the first two principal components

Applying correlation

Predicting the values

Comments
Post a Comment